

What you read in this article:
Apache Airflow
What is Apache Airflow, and how does it differ from other similar products?
I’m Arsalan Mirbozorgi;
Apache Airflow is an open-source application for creating, scheduling, and monitoring workflows programmatically. It is among the most useful and powerful tools for orchestrating processes or pipelines used by Data Engineers. Your data pipelines’ dependencies, logs, code, progress, trigger tasks, and success status can all be conveniently viewed in a single place.
Directed Acyclic Graphs (DAGs) of tasks can be created using Airflow. Airflow’s user-friendly interface makes it easy to see pipelines running in production, monitor progress, and troubleshoot any difficulties that may arise during production. When a job is finished or fails, it can send an email or Slack message to notify you. Complex business logic may be orchestrated using Airflow since it is distributed, scalable, and flexible.
What is the Purpose of Airflow?
Data pipelines and workflows can be scheduled and orchestrated with Apache Airflow. In data pipeline orchestration, complicated data pipelines from several sources are sequenced, coordinated, scheduled, and managed. They supply ready-to-use data sets for use by both business intelligence applications and machine learning models supporting big data applications.
Directed Acyclic Graphs (DAGs) are used to model these operations in Airflow (DAG). Let’s have a look at a workflow/DAG in the context of preparing pizza.
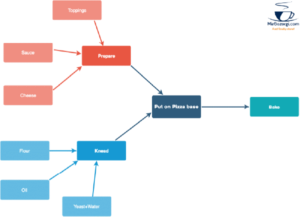
Pizza
End goals like developing visualizations of sales data from the previous day are common in workflows. DAG depicts how each step is reliant on multiple other stages that must be completed first. You need flour, oil, yeast, and water to knead the dough, for example. In the same way, you’ll need the ingredients for pizza sauce. This is also true when you plan to generate a visual representation of your past day’s sales data.
Since kneading the dough and making the sauce are not interdependent, they can be done in tandem using this model. Similarly, you may need to load data from many sources to generate your visualizations. A Dag that generates graphics based on the previous day’s sales is shown here.
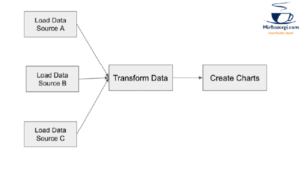
Generated Dag
As a result, the ML models developed by data scientists using efficient, cost-effective, and well-organized data pipelines can be better-tuned and more accurate. A suitable framework for orchestrating jobs running on any big data engine is Airflow, which is natively connected with Hive, Presto, and Spark. Airflow is increasingly being used to orchestrate ETL/ELT jobs by organizations.
Components of Apache Airflow’s Architecture
Knowing how Airflow’s many parts interact with each other allows you to orchestrate data pipelines more efficiently.
The Airflow pipelines are written in Python, allowing for the creation of dynamic pipelines. This makes it possible for programmers to design code that dynamically creates pipelines.
Your own operators and executors may be defined, and the library may be extended to satisfy your environment’s needs.
Streamlined: Airflow pipelines are clear and concise. Airflow’s Jinja templating engine makes it easy to customize your scripts.
Airflow’s modular design and usage of a message queue allow it to work with any number of employees.
Getting Apache Airflow up and running
On a laptop, Apache Airflow can be installed and used in a variety of ways. There are three ways to put it up in this post. There are three sorts of executors to choose from in each method. We select a single executor for each approach:
- Virtualenv and pip are used to create a basic setup. The SequentialExecutor is used to test DAGs on a local development computer in this configuration.
- An example of a Docker setup in which we use Redis as a queue to execute CeleryExecutor.
- Helm is used to configure Kubernetes for running KubernetesExecutor on a cluster.
Using Apache Airflow for ETL/ELT is advantageous
A few of the reasons why Airflow is superior to other platforms are as follows:
Airbnb established Airflow in 2015, and it has since grown into a thriving community. Since its inception, the Airflow Community has grown in size and stature. The number of people contributing to Airflow is increasing at a healthy rate.
Apache Airflow‘s extensibility and functionality allow it to be used in a variety of ways. Adding custom hooks/operators and other plugins makes it easier for users to develop custom use cases without relying on Airflow Operators. Many new features have been introduced to Airflow since its inception. Airflow was built by a team of Data Engineers to solve a wide range of Data Engineering Problems. Many essential features are being worked on that will help improve Airflow’s performance and stability, even though it isn’t perfect.
Airflow pipelines can be generated dynamically since they are configured as code (Python). This will result in writing codes that dynamically build pipeline instances. There is no one-size-fits-all approach to our data processing.
As compared to a step-based declaration, Airflow models more closely with a dependency-based declaration. As the total of stages increases, it becomes increasingly difficult to describe a single step. This paradigm of work, which establishes a linear flow based on defined dependencies, is supported by Airflow. Another advantage of using code to maintain pipelines is the ability to track and document changes. Roll-forward and roll-back are more easily supported in Airflow than other solutions, providing greater detail and accountability for changes over time. Even though not everyone employs this method, Airflow will adapt to your data practices.
Apache Airflow on Qubole
You can create, schedule, and monitor complicated data pipelines using Airflow on Qubole. Take the hassle out of managing Airflow clusters with one-click start and stop. Your data pipeline will operate as smoothly as possible thanks to seamless connections with Github and AWS S3. In addition, users can input commands to Qubole using capabilities such as the Airflow QuboleOperator, which gives them greater programmatic flexibility.
The following features have been added to Qubole Airflow to make it easier to use:
The DAG Explorer
Qubole has released a tool to upload Airflow Python DAG files to Amazon S3, edit them in place, and periodically sync them with Airflow clusters for continuous development, integration, and deployment of Airflow DAGs (in the background). Airflow process and log files are also available for download via the Airflow cluster page. As a result, complicated workflows can be developed rapidly, and the files remain in sync.
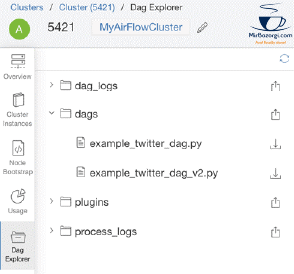
Dag Explorer
Learn about DAGs, tasks, and how to write a DAG file for Airflow by watching this video. DAG runs, and Task instances are also discussed in this episode.
https://youtu.be/2nhdhIYueIE
Anaconda Virtual Environment
Anaconda virtual machines may now run Airflow. When constructing an Airflow cluster, users have the option of selecting a Python version. As soon as you select Python 3.5, you’ll be able to use the Anaconda environment and the Qubole UI to handle your cluster’s installation and removal of packages.
Anaconda
Using Anaconda’s Anaconda environment, users may conduct machine learning and data science projects by creating sophisticated data pipelines. Qubole’s package management capability also allows people to install other packages designed for data science workloads within the Anaconda environment on the fly.
Using Apache Airflow on QDS
For data teams who want to build dynamic, extendable, and scalable pipelines in the cloud, Airflow on QDS provides a fully managed and automated cluster lifecycle management for Airflow in the cloud.
Using Qubole’s automated cluster lifecycle management infrastructure, Airflow clusters on QDS may use the same infrastructure as Hadoop, Spark, Presto, and HBase clusters. So you can use one-click provisioning of clusters, define Airflow specific settings, configure clusters to launch safely within your VPCs and Subnets and choose from more than 40 AWS instance kinds.
To help you combine Airflow with your data pipelines in QDS, we introduced the Qubole Operator in this article. In order to use Airflow to manage complex data pipelines while submitting jobs directly to QDS, this operator is required.
Upon launching Airflow clusters, you will have access to a web server for monitoring your processes. Additional monitoring is provided by Ganglia and Celery Dashboards provided by Qubole.
We’ve made the codebase more trustworthy by expanding it. When Airflow goes down, rebooting the cluster will immediately restore all Qubole Operator jobs to their previous condition.
The Airflow web server’s loading time has been greatly reduced by implementing a mechanism to cache assets. In addition, we’ve made it easier to switch between Airflow and QDS. Big Data workload processing necessitates tighter control over data pipeline monitoring.
Existing roles, users, and group-based security are used for all actions on Airflow clusters in production on QDS. Airflow clusters and workflows can now be authorized without the requirement for additional/custom ACL or security procedures.







