

What you read in this article:
Introduction to RabbitMQ and Kafka Technologies
I, Arslan Mirbzergi, would like to discuss in this article complete information about RabbitMQ and Kafka technologies, their applications and advantages. For some reason, many Developer believe that RabbitMQ and Kafka technologies can replace each other. Although this is true in some cases, there are various fundamental differences between these platforms.

Architecting microservice-based systems, I frequently run into the question, “Should I use RabbitMQ or Kafka?” as a software architect. Many developers, for some reason, consider these two methods to be equivalent. These platforms are similar on the surface but differ on the inside for various reasons.
The result is that each scenario calls for a unique solution, and picking the wrong one could have serious ramifications for your ability to design, develop, and maintain your software solution in the long run
Asynchronous messaging patterns will be introduced at the beginning of this piece. Next, RabbitMQ and Kafka’s internal structures are presented. Part 2 discusses the key differences between the two platforms, their various benefits and drawbacks, and how to decide between them.
Asynchronous Messaging Patterns
Asynchronous messaging is a messaging strategy in which a producer creates messages independently of how a consumer processes them. Message queuing and publish/subscribe are the two most common messaging patterns encountered when working with messaging systems.
Message queueing
This communication pattern decouples producers from consumers by utilizing message queues to hold messages while they are being processed. Multiple producers can use the same queue, but once a consumer has processed a message, it is locked or removed and is no longer available. A single person only consumes a message.
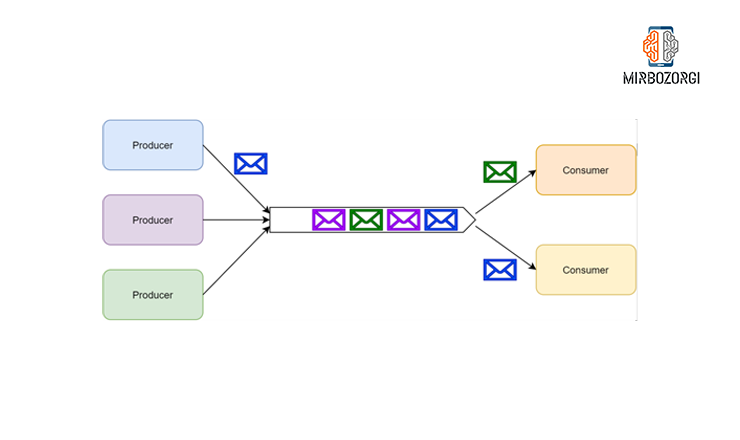
Publish/Subscribe
Multiple subscribers can receive and process the same message simultaneously using the publish/subscribe (or pub/sub) communication pattern.
A publisher can use this pattern to alert all subscribers to a change in the system. Pub/sub is frequently associated with the term topics on many queuing platforms. Topics in RabbitMQ are a specific implementation of pub/sub (more specifically, an exchange), but for the purposes of this article, I refer to topics as a representation of pub/sub as a whole.
Subscriptions can be broadly divided into two categories:
- Ephemeral subscriptions are those that last only as long as the customer has access to the subscription service. When a user logs out, their entire, unprocessed messages are deleted.
- If you have a long-term subscription, it will remain active if you don’t delete it. The messaging platform remembers the user’s subscription even if the computer is turned off, so message processing can be resumed later.
RabbitMQ
RabbitMQ is a message broker implementation, also known as a service bus. Both of the aforementioned messaging patterns are natively supported. ActiveMQ, ZeroMQ, Azure Service Bus, and Amazon Simple Queue Service are popular message brokers (SQS). Most of the concepts discussed in this article apply to all of these implementations.

Queues
Classic message queuing is built-in to RabbitMQ. Publishers can send messages to a named queue that a developer has defined. Messages are retrieved by consumers and processed by them using the same queue.
Message Exchanges
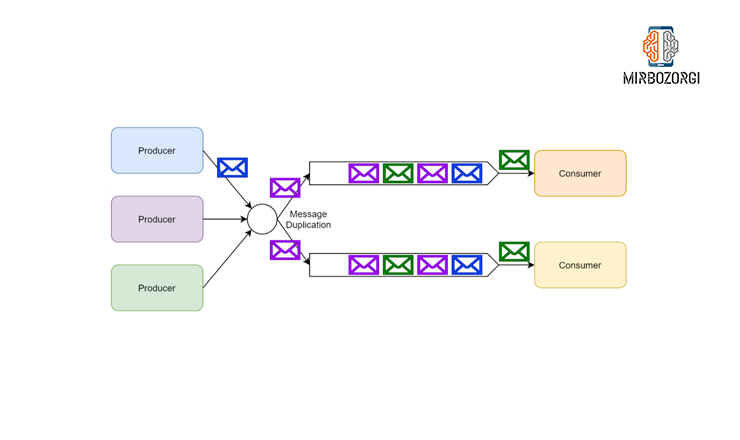
RabbitMQ uses message exchanges to implement pub/sub. When the publisher posts a message to a message board, they have no idea who will be reading it.
Each user who wants to join an exchange must first create a queue, and the message exchange then distributes the messages it has produced to the users in the queue. As a result, certain subscribers will only receive messages that meet certain criteria.
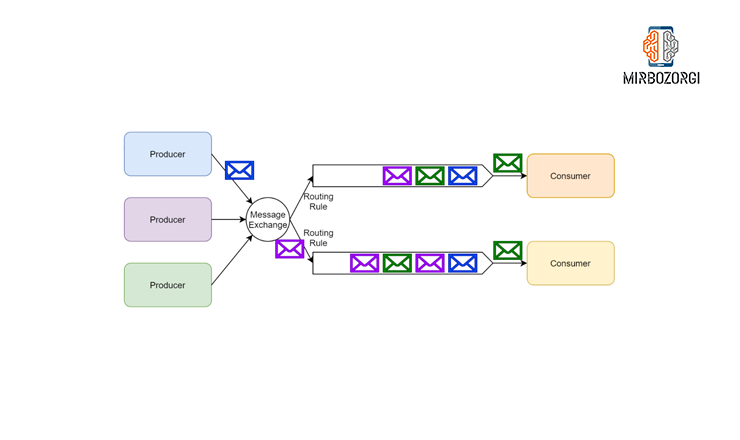
RabbitMQ supports both ephemeral and durable subscriptions, which should be noted. The RabbitMQ API lets a user select the type of subscription they want to use.
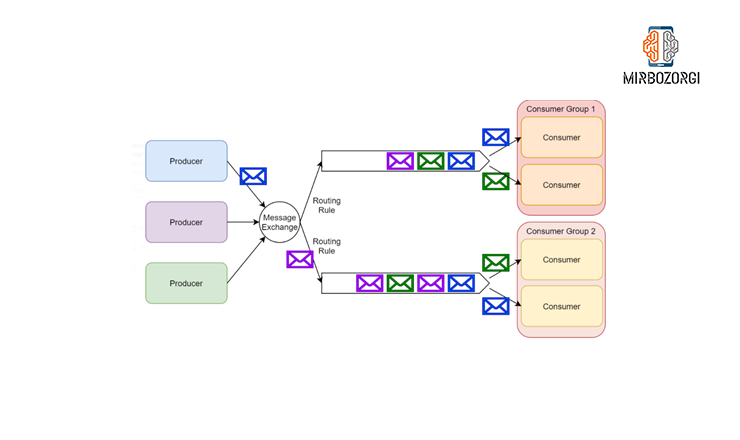
A hybrid approach can be created using RabbitMQ’s architecture, in which some subscribers form consumer groups that compete to process messages on a particular queue. While also allowing some subscribers to scale up to deal with received messages, we’ve implemented the pub/sub pattern in this manner.
Apache Kafka
RabbitMQ supports both ephemeral and durable subscriptions, which should be noted. The RabbitMQ API lets a user select the type of subscription they want to use.
A hybrid approach can be created using RabbitMQ’s architecture, in which some subscribers form consumer groups that compete to process messages on a particular queue. While also allowing some subscribers to scale up to deal with received messages, we’ve implemented the pub/sub pattern in this manner.

Topic
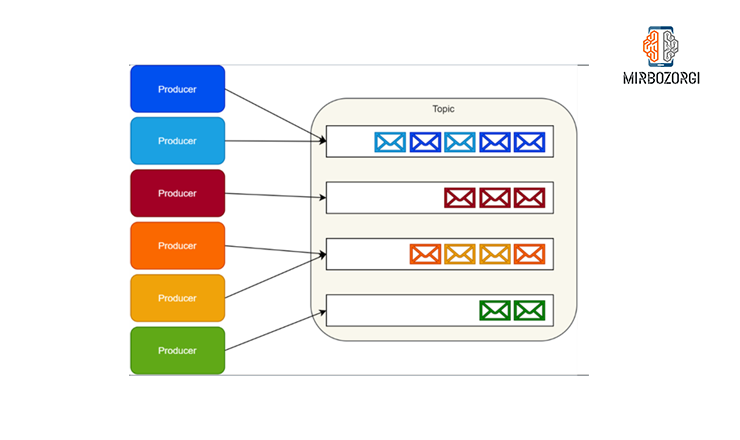
Kafka does not run the Queue concept. Instead, it stores a set of record in categories called Topic. For each Topic, Kafka retains a partitioned report of messages. Each partition is a special and immutable order of record that messages are constantly added to.
Kafka adds messages to their partitions when they arrive, and by default, uses Round-robin to play messages uniformly among partitions.
Producers can change this to create Logical stream message. For example, in a Multitenant app, you may want to create logical stream messages according to tenant ID of each message. In an IoT scenario, identity map of any Producer may be needed to exist continuously on a specific partition. It should ensure that for Consumer, the delivery of all messages from Logical stream to the same partition is guaranteed.
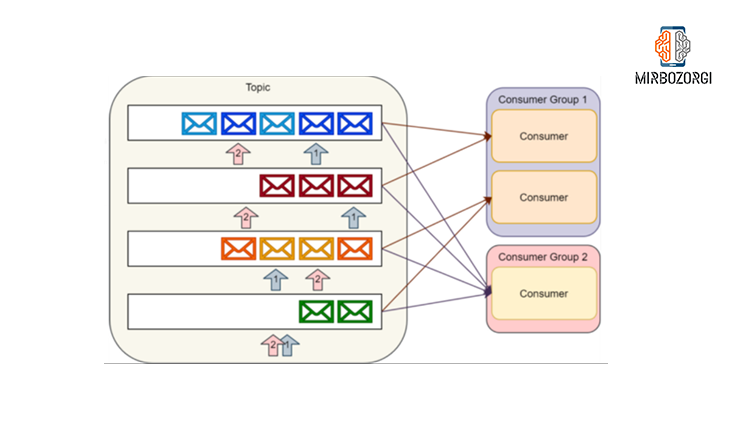
Consumers read and use messages successively by registering and keeping Offset Indx on partitions. A Consumer can use multiple Topics and rate the number of available partitions. As a result, when creating a topic, you should carefully consider the amount of operational throughput from Messaging in that topic. A group of Consumers who work together to use a Topic is called the Consumer Group. Kafka’s API typically controls the partition processing balance between consumers in a Consumer group and the current storage of Consumers’ Offsets.
RabbitMQ supports both ephemeral and durable subscriptions, which should be noted. The RabbitMQ API lets a user select the type of subscription they want to use.
A hybrid approach can be created using RabbitMQ’s architecture, in which some subscribers form consumer groups that compete to process messages on a particular queue. While also allowing some subscribers to scale up to deal with received messages, we’ve implemented the pub/sub pattern in this manner.
Implementing messaging patterns with Kafka
Apache Kafka is not a message broker implementation. As an alternative, it’s a platform for dispersed live streaming.
The storage layer of Kafka uses a partitioned transaction log instead of queues and exchanges like RabbitMQ. However, these things are outside the scope of this article, as Kafka also provides a Streams API for processing streams in real-time and a Connectors API for easy integration with different data sources.
Cloud service providers offer different approaches to the storage layer of Kafka. Azure Event Hubs and, to some extent, AWS Kinesis Data Streams are examples of these solutions. It’s also worth noting that there are cloud-specific and open-source alternatives to Kafka’s stream processing capabilities.
Topics
The concept of a queue is not implemented in Kafka. Rather, Kafka organizes his data into topics, which are like subcategories within a larger category.
Kafka keeps a partitioned message log for each topic. Data is continually added to each partition in an ordered, unchanging sequence.
As new messages arrive, Kafka adds them to the existing partitions. It distributes messages evenly across partitions by default using a round-robin partitioner.
Produced messages can be created by modifying this behavior. Consider a scenario in which we want to create logical message streams based on the tenant ID of each message. Having the identity of each manufacturer constantly map to a specific partition may be desirable in an IoT scenario. Message delivery in order to customers is ensured by mapping all messages from the same logical stream to the same partition.
Using the pub/sub pattern, Kafka’s implementation is a perfect fit.
A producer is able to send messages to a specific topic, and multiple consumer groups are able to consume the same message. Each customer segment can handle the load on its own. Given that customers’ partition offsets are preserved, they can opt for a durable subscription that keeps its offset constant across restarts or an ephemeral subscription that discards the offset and starts over from the most recent record in each partition upon each restart.
However, the message-queuing pattern isn’t quite right for it. In order to simulate classic message queuing, we could have a topic with only one consumer group. Despite this, there are several drawbacks. This article’s second half goes into greater depth about the subject.
It’s important to know that Kafka keeps messages in partitions for a predetermined period of time, regardless of whether consumers consume them or not. Because of this, customers can go back and reread previous messages. In addition, the storage layer of Kafka can be used by developers to implement mechanisms like event sourcing and audit logging.
Conclusion
They may be applied interchangeably at times, but the implementations of RabbitMQ and Kafka are vastly different. They are not tools in the same way; one is a message broker, and the other is a platform for distributed streaming.
Architects should be aware of these differences and actively consider which solution type to use in a specific scenario. Second, we’ll look at the differences between the two and see when to use each one.
And in the end,
While RabbitMQ and Kafka can sometimes be replaced, their implementations and implementations are very different. As a result, we can’t put them together in a group of tools. One of them is the message intermediary and the other is a distributed Streaming platform. As a result, we need to recognize these differences and then examine which of these solutions we can use for a particular problem.








I have to say I frequently wondered on this subject , never actually took the time to research it, thanks for the post.