

In this article, I intend to explain the recognition of Spring Batch. Many applications in the enterprise field require mass processing to get things done. Like:
- Automated and complex processing of large amounts of information that is most efficient is processed without user interaction. This operation usually involves time-based events (such as end-of-month calculations, notices, or correspondence).
- Many programs perform complex calculations periodically or instantaneously on big data. For example determining insurance benefits or adjusting rates.
- Integration of information that is usually received from internal and external systems and requires formatting, validating and processing records. Batch processing is used to process billions of transactions daily for companies.

What you read in this article:
Definition of Spring Batch:
Spring Batch is a simple and comprehensive framework that is essential for the development of the daily operations of enterprise systems. Based on spring framework features (productivity, POJO-based development approach, and general ease of use), this provides developers with access to more advanced enterprise framework services.
This framework uses the traditional Batch architecture, in which a reposittory is responsible for timing and interacting with other tasks. Here a job can take more than one step. At each stage, a sequence of actions such as reading, processing and writing data is performed.
Applications:
- Read lots of records from databases, files or queues
- Processing data in different ways
- Write data as modified
- Performing processes periodically
- Simultaneous execution of job in parallel
- Mass parallel execution
- Manual or scheduled restart after downtime
- Batch transactions, for items with the size of the saved procedures/scripts
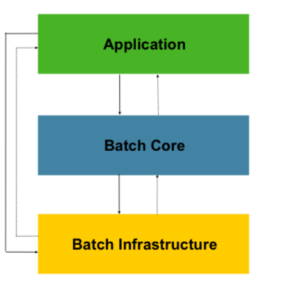
Architecture:
Spring Batch is designed by testing on a wide variety of users. The figure below represents layered architecture and ease of use.
New Spring Batch 4.3 Fixtures:
- Synchronized New ItemStreamWriter
- JpaQueryProvider new to name queries
- New implementation of JpaCursorItemReader
- Implementation of the new JobParametersIncrementer
- Support for GraalVM
- Java Records Support
@Bean public FlatFileItemReader<Person> itemReader() { return new FlatFileItemReaderBuilder<Person>() .name("personReader") .resource(new FileSystemResource("persons.csv")) .delimited() .names("id", "name") .fieldSetMapper(new RecordFieldSetMapper <> (Person.class)) .build(); }</Person></Person> - Use bulk text in RepositoryItemWriter
- Use bulk text in MongoItemWriter
- Improve start/stop job schedules
Dependency :
As we stated earlier, Spring Batch requires the SQLite database to run. Therefore, first, we need to add the following in the pom.xml file:
<dependency>
<groupId>org.xerial</groupId><artifactId>sqlite-jdbc</artifactId><version>3.15.1</version>
</dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-oxm</artifactId><version>5.3.0</version>
</dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-jdbc</artifactId><version>5.3.0</version>
</dependency><dependency><groupId>org.springframework.batch</groupId><artifactId>spring-batch-core</artifactId><version>4.3.0</version>
</dependency>
And also a Batch config file with the following features:
<!-- connect to SQLite database -->
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="org.sqlite.JDBC" />
<property name="url" value="jdbc:sqlite:repository.sqlite" />
<property name="username" value="" />
<property name="password" value="" />
</bean>
<!-- create job-meta tables automatically -->
<jdbc:initialize-database data-source="dataSource">
<jdbc:script
location="org/springframework/batch/core/schema-drop-sqlite.sql" />
<jdbc:script location="org/springframework/batch/core/schema-sqlite.sql" />
</jdbc:initialize-database>
<!-- stored job-meta in memory -->
<!--
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean">
<property name="transactionManager" ref="transactionManager" />
</bean>
-->
<!-- stored job-meta in database -->
<bean id="jobRepository" class="org.springframework.batch.core.repository.support.JobRepositoryFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="transactionManager" ref="transactionManager" />
<property name="databaseType" value="sqlite" />
</bean>
<bean id="transactionManager" class=
"org.springframework.batch.support.transaction.ResourcelessTransactionManager" />
<bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>
And the job config file:
<import resource="spring.xml" />
<bean id="record" class="com.baeldung.spring_batch_intro.model.Transaction"></bean>
<bean id="itemReader" class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="input/record.csv" />
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name="names" value="username,userid,transactiondate,amount" />
</bean>
</property>
<property name="fieldSetMapper">
<bean class="com.baeldung.spring_batch_intro.service.RecordFieldSetMapper" />
</property>
</bean>
</property>
</bean>
<bean id="itemProcessor"
class="com.baeldung.spring_batch_intro.service.CustomItemProcessor" />
<bean id="itemWriter" class="org.springframework.batch.item.xml.StaxEventItemWriter">
<property name="resource" value="file:xml/output.xml" />
<property name="marshaller" ref="recordMarshaller" />
<property name="rootTagName" value="transactionRecord" />
</bean>
<bean id="recordMarshaller" class="org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name="classesToBeBound">
<list>
<value>com.baeldung.spring_batch_intro.model.Transaction</value>
</list>
</property>
</bean>
<batch:job id="firstBatchJob">
<batch:step id="step1">
<batch:tasklet>
<batch:chunk reader="itemReader" writer="itemWriter" processor="itemProcessor" commit-interval="10">
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>
And in the end,
In this paper, we have tried to provide explanations about spring batch recognition.
Mirbazorgi’s website aims to help you learn and fix your problems by providing articles and practical experiences. Email me if you have any questions.







