

What you read in this article:
Kafka’s Metaphor, KubeMQ
I’m Arsalan Mirbozorgi;
There are various benefits to using a current, Kubernetes-native message queue, like KubeMQ, when implementing Kafka in Kubernetes.
There are many moving pieces in modern apps. Front-end interfaces activate payment processing transactions, which in turn trigger production and shipping events in the most basic fulfillment center application. Regardless of the underlying network or the presence of other services, these services require a dependable means of communication.
There must be some sort of service “post office” to keep track of all the requests and alerts going back and forth in order for these intricate activities to take place. The message queue is the means through which this is accomplished. A message queue is considered a specialized application that serves as an intermediary in a distributed or between separate applications. An application service can be decoupled from each other, guaranteeing that the message is processed even if the recipient is unavailable. It is the message queue’s job to ensure that all messages are received.
For example, message queues can be used for the following:
- Parallel processing amongst different apps.
- Reliable communication between the components of microservice-based applications.
- Throttling and transaction ordering.
- Batching is a technique that can improve the efficiency of data processing.
- An application’s ability to grow and change with the needs of the business is critical to its success.
- Apps that must be able to recover from unexpected failures and crashes.
- Limiting the number of resources that long-running processes can use.
In the sphere of message queues, there is no scarcity of companies offering their services. Cloud giants like Amazon Web Services (AWS), Microsoft Azure (Azure Service Bus), and Google Cloud (Google Pub/Sub) all have their own versions of AWS Simple Queue Service. Separate general-purpose messaging systems, such as Apache’s active-MQ and RabbitMQ, are available as well.
By introducing KubeMQ, a modern message queue for Kubernetes, this article demonstrates how enterprises implementing or already using Kafka on Kubernetes can take advantage of KubeMQ.
Introduction of Apache Kafka
KubeMQ‘s full potential can only be realized if we spend some time with Kafka. Engineers at LinkedIn were the first to use Kafka to track user activity on LinkedIn. While first developed by the Apache Software Foundation (ASF), Kafka was eventually distributed as open-source software.
80% of the Fortune 100 firms utilize and trust Kafka, according to Apache. Despite being free and open-source, it has a reputation for being one of the most flexible systems in the industry. Even in constrained network conditions, it can execute complicated functions with data streams. Kafka has several commercial offerings, thanks to its widespread support in the online community. As an example, AWS and Confluent both offer managed Kafka.
Restrictions imposed by Kafka
Despite its widespread use, Kafka isn’t always the best solution for message queuing applications. On-premise clusters and high-end multi-VM installations can benefit from its monolithic architecture. Given how much memory and storage Kafka demands, quickly putting up a multi-node cluster on a solo workstation for testing reasons can be difficult.
Putting it simply, integrating Kafka with your infrastructure isn’t a simple task. Kubernetes-based architectures are particularly susceptible to this.
A Kubernetes-based Kafka deployment has several moving pieces, as seen in the diagram below. For a basic Kubernetes cluster, you’ll also need to install and integrate all Kafka components using a package manager like Helm. An orchestrator, like ZooKeeper or Mesos, can be used to manage the brokers and topics in Kafka. Dependencies, logs, and partitions are just some of the other areas that need to be addressed. Things won’t work if even one component is missing or misconfigured—deploying Kafka isn’t easy.
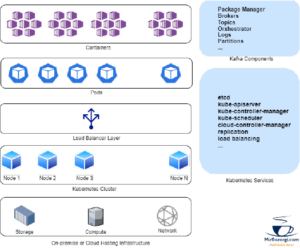
Kafka on Kubernetes Architecture
In order to keep the Kubernetes cluster running well, adding a new Kafka node necessitates extensive manual intervention. Managing and ensuring a solid backup and recovery strategy is difficult since Kafka clusters with many nodes are difficult to disaster-proof. When a pod fails, the orchestrator starts up a new one. This is not the case with Kafka, which does not have such fail-safe mechanisms built-in.
A third-party solution is required to monitor Kafka, Zookeeper, and Kubernetes deployments effectively.
Introducing KubeMQ
In the spirit of Kubernetes, KubeMQ was created from the bottom up as a messaging service. KubeMQ is designed to be stateless and ephemeral in accordance with container architecture best practices. In other words, a KubeMQ node will stay stable, predictable, and reproducible during its entire existence. Nodes are shut down and replaced if configuration updates are required.
KubeMQ, unlike Kafka, has a zero-configuration set up, requiring no post-installation configuration tweaks.
- KubeMQ can accommodate all kinds of message patterns. Supports the following: Message broker and message queue
- Subscribing and unsubscribing from a feed
- Request/Answered (synchronous, asynchronous)
- Only One Delivery Is Expected
- Delivered At Least Once
- Streams of data
- RPC
However, Kafka is limited to a few features, such as Streaming Pub/Sub and persistence. Kafka does not support RPC or Request/Reply patterns at all.
KubeMQ has a smaller footprint than Kafka, making it a better choice for consuming resources. Only 30MB of space is needed for the KubeMQ docker container to run. Fault tolerance and faster deployments can be achieved because of the compact footprint. Like Kafka, KubeMQ may be added to a Kubernetes development environment on a local workstation easily. KubeMQ, on the other hand, is scalable enough to run on hundreds of on-premise and cloud-hosted nodes in a hybrid environment. The command-line interface tool for KubeMQ, kubemqctl, lies at the heart of this deployment ease.
Additionally, KubeMQ is faster than Kafka. The fast operation was ensured by the fact that Kafka was implemented in Java and Scala, and KubeMQ was written in Go. One million messages were processed twice as fast with KubeMQ compared with Kafka in an internal benchmark test.
A channel is a sole object that developers will need to build under KubeMQ‘s “configuration-free” mode. KubeMQ‘s Raft replaces ZooKeeper in the role of brokers, exchanges, and orchestrators.
You don’t have to manually connect third-party observability tools when using dashboards from Prometheus and Grafana, which are completely linked with KubeMQ from a monitoring perspective. However, KubeMQ‘s native interaction with technologies allows you to continue using your current logging and monitoring solutions.
- For monitoring, we use Fluentd, Elastic, and Datadog.
- A tool for keeping track of logs
- Open Tracing and Jaeger, for tracing
Integration with CNCF tools is typically not supported because Kafka is not native to the Cloud Native Computing Foundation (CNCF) ecosystem.
The open-source gRPC remote procedure call system, which is well renowned for its excellent interoperability with Kubernetes, can be configured to provide connectivity if desired. There is no guarantee that the unique connecting technique developed by Kafka will produce similar outcomes.
Migration from Kafka to KubeMQ in a Transparent Manner
KubeMQ‘s deployment and operation are simple, making it easy to migrate from Kafka to KubeMQ.
Using the KubeMQ Kafka connector is a good place to start. In order to receive the desired messages from Kafka, the KubeMQ target and source connections have been set up. Source connectors for KubeMQ consume messages from a Kafka source topic as subscribers, transform the messages to KubeMQ message formats, and then publish the messages to an internal journal. In order to transmit the converted messages to a target topic in Kafka, the KubeMQ target connectors subscribe to an output journal. In the diagram below, you are able to see a high-level architecture.
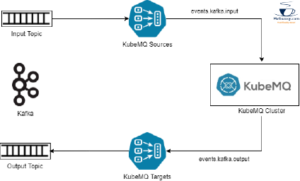
Kafka Integration with KubeMQ
Additionally, KubeMQ supports all messaging patterns that Kafka does, as well. On the other hand, streaming and persistence are the only options for Kafka‘s Pub/Sub. Request/Response (sync, async), at least one delivery, streaming patterns, and RPC are all supported by KubeMQ, a message queue, and a broker. Migration from Kafka to KubeMQ does not necessitate refactoring application code or accommodating complex logic modifications.
Conclusion
Most workloads will benefit from KubeMQ‘s simplicity, small footprint, and container-first integration. It will also save a great amount of time because of the minimal configuration required. Migration, as previously stated, is a simple process.
A six-month free trial of KubeMQ is included with the free download. Using KubeMQ with OpenShift can be done through the Red Hat Marketplace. Also, it’s available for use on all of the major public cloud platforms like Google Cloud Platform (GCP), AWS, Azure, and DigitalOcean (DO).







