

Before considering more complex solutions, it’s usually a good idea to see if single-threaded, single-process batch jobs can suit your objectives first. If you want to know if the most straightforward solution will work for you, measure the performance of a real job first. Even with standard technology, you can read and write a file of several hundred megabytes in less than a minute.
What you read in this article:
Parallel Processing
While some capabilities of Spring Batch are discussed elsewhere, this article provides a good starting point for those who want to begin constructing a job that uses some parallel processing. Parallel processing can be done in two ways at a high level:
- Multi-threaded, single-process
- Multi-process
As a result, these are categorized as the following:
- A multi-threaded procedure (single process)
- Moving in the same path at the same time (single process)
- Stepping on a Remotely Controlled Surface (multi-process)
- Creating a Step by Step Divider (single or multi-process)
We begin by looking at the single-process alternatives. After that, we’ll have a look at the multi-processing possibilities.
Multi-threaded application
You may begin parallel processing right away by adding a TaskExecutor to your Step setup.
While utilizing java configuration, the following example shows how a TaskExecutor may be added:
Java Configuration
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor(“spring_batch”);
}
@Bean
public Step sampleStep(TaskExecutor taskExecutor) {
return this.stepBuilderFactory.get(“sampleStep”)
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.build();
}
A reference to another bean specification that implements the TaskExecutor interface is used in this example. Please check the Spring User Guide for further information on TaskExecutor implementations. A SimpleAsyncTaskExecutor is the most basic multi-threaded TaskExecutor.
As a result, the step executes in a different thread for each chunk of data (each commit interval) that it processes and writes. This means that there is no definite order in which the things are processed, and a chunk may comprise items that are not consecutive compared to the single-threaded scenario. There is a throttle limit of 4 in the tasklet settings besides any constraints set by the task executor (such as whether a thread pool supports it). To guarantee that a thread pool is wholly utilized, you may need to increase this value.
Using Java settings, the builders make it possible to reach the throttle limit, as demonstrated by the following example:
Java Configuration
@Bean
public Step sampleStep(TaskExecutor taskExecutor) {
return this.stepBuilderFactory.get(“sampleStep”)
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.throttleLimit(20)
.build();
}
Keep in mind that any shared resources you use in this stage, such as a DataSource, may impose concurrency limits. Make the resource pool as big as the number of concurrent threads you want in the step.
Using multi-threaded Step implementations for several popular batch use cases has some practical drawbacks. Stateful participants (such as readers and writers) are common in Steps. Components cannot be used in a multi-threaded Step if the state is not separated per thread. As a result, most of Spring Batch’s prebuilt readers and writers are not designed for multi-threading. ParallelJob in the Spring Batch Samples explains how to keep track of things processed in a database input table using a process indicator (see Preventing State Persistence), a stateless or thread-safe reader, or writer.
Spring Batch includes several ItemWriter and ItemReader implementations. To avoid issues in a concurrent environment, the Javadoc will usually tell you if the method is thread-safe or not by checking the implementation to see if any state is an option if no information is available in the Javadoc. You can use the provided SynchronizedItemStreamReader to decorate a reader that is not thread-safe, or you can use it in your synchronizing delegate. The call can be synchronized to read() and still complete your step faster than in a single-threaded system as long as processing and writing are the most expensive components of the chunk.
Parallel steps
It is possible to parallelize an application’s logic in a single process if the logic can be divided into discrete responsibilities and given to individual phases. Configuring and using Parallel Step is simple.
The following example shows how to run steps 1 and 2 in parallel with step 3 using Java configuration:
Java Configuration
@Bean
public Job job() {
return jobBuilderFactory.get(“job”)
.start(splitFlow())
.next(step4())
.build() //builds FlowJobBuilder instance
.build(); //builds Job instance
}
@Bean
public Flow splitFlow() {
return new FlowBuilder<SimpleFlow>(“splitFlow”)
.split(taskExecutor())
.add(flow1(), flow2())
.build();
}
@Bean
public Flow flow1() {
return new FlowBuilder<SimpleFlow>(“flow1”)
.start(step1())
.next(step2())
.build();
}
@Bean
public Flow flow2() {
return new FlowBuilder<SimpleFlow>(“flow2”)
.start(step3())
.build();
}
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor(“spring_batch”);
}
To specify which Task Executor implementation should be used for running each flow, the customizable task executor is employed. To run the steps in parallel, an asynchronous TaskExecutor must be used instead of the default SyncTaskExecutor. Before aggregating the departure statuses and transitioning, the job makes sure that every flow in the split has been completed.
See the Split Flows section for more information.
Remote Chunking
When using remote chunking, the Step processing is divided among several processes that communicate via middleware. In the below picture, you can see the pattern:
The manager is a single process, whereas the employees are distributed over numerous machines. Managers are not bottlenecks in this paradigm; thus, processing must be more expensive than item reading (as is often the case in practice).
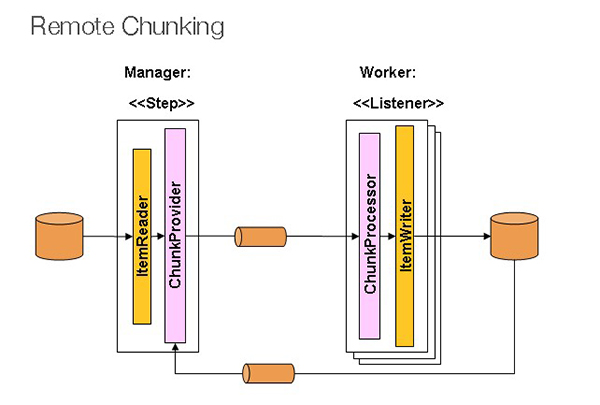
ItemWriter is substituted by Spring Batch Step generic version that understands how to send messages in chunks of items to the middleware. For whatever middleware is being used, the workers are just regular implementations of the MesssageListener interface, which are typical listeners for whatever middleware is being used (for example, JMS would be MesssageListener implementations). As a side benefit of employing this pattern, you don’t have to worry about the reader, processor, and writer components because they are all available off the shelf (the same as would be used for local execution of the step). The items are dynamically distributed, and the middleware distributes the work so that load balancing is automatic if the listeners are all eager consumers.
There must be a single consumer for each message, and the middleware must be persistent. However, additional grid computing and shared memory products (like JavaSpaces) exist.
Partitioning
It is possible to divide a Step execution and run it remotely using an SPI provided by Spring Batch. When the distant participants are Step instances, they can be used for local processing. In the figure below, you can see the pattern:
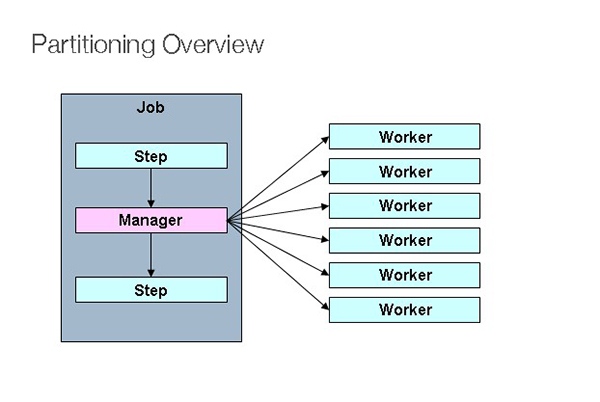
There is a Step instance on the left-hand side that is tagged as a manager for a specific Job. Each worker depicted here is a Step, which might replace the manager in this scenario, resulting in a similar job conclusion. However, the workers may be local threads of execution rather than remote service providers. Messages sent from the manager to the workers in this pattern do not need to be long-lasting or guaranteed to reach their intended recipients. Workers have only executed once and only once for each Job execution, thanks to Spring Batch information in the Job Repository.
Spring Batch has two strategy interfaces that need to be implemented for each environment, and the SPI consists of a custom version of the step (the PartitionStep). StepExecutionSplitter and PartitionHandler interfaces are presented in the sequence diagram below.
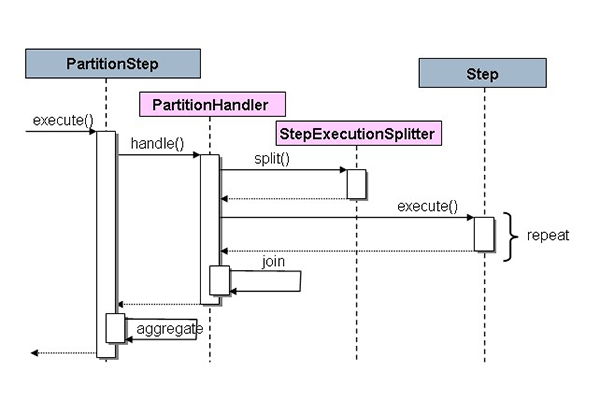
“Remote” workers can be many objects or processes, demonstrated by the PartitionStep that is driving the execution.
PartitionStep configuration using Java configuration is shown in the following example.
Java Configuration
Bean
public Step step1Manager() {
return stepBuilderFactory.get(“step1.manager”)
.partitioner(“step1”, partitioner())
.step(step1())
.gridSize(10)
.taskExecutor(taskExecutor())
.build();
}
As with multi-threaded steps, the grid-size parameter prevents the task executor from becoming overwhelmed by requests from a single step, like the throttle-limit attribute.
The Spring Batch Samples unit test suite includes a simple example that may be duplicated and enhanced (see partition*Job.XML settings).
If you have a partition called “step1:partition0,” Spring Batch creates a step execution for it. Step 1: The manager is preferred by many individuals because it is consistent with the rest of the steps. An alias can be used for this phase (by specifying the name attribute instead of the id attribute).
PartitionHandler
The PartitionHandler component partitions remoting or grid environments. It sends StepExecution requests wrapped in a fabric-specific format like DTO to the remote Steps. It doesn’t need any knowledge of partitioning the input data or aggregating the outcome of numerous Step executions. Resilience and failover are often built into the fabric; thus, it doesn’t need to be aware of them. On the other hand, Spring Batch always ensures the restart ability irrespective of the fabric. Restarting a failed Job re-runs the unsuccessful Steps.
Own web services, JMS, shared memory grids (like Terracotta or Coherence), and grid execution fabrics can all use the PartitionHandler interface to construct their custom implementations of the PartitionHandler interface (like GridGain). Spring Batch does not include implementations for any proprietary grid or remote fabric.
PartitionHandler implementations by Spring Batch might be handy for executing Step objects locally on separate threads using the TaskExecutor technique. TaskExecutorPartitionHandler is the name of the implementation.
Configuration of TaskExecutorPartitionHandler may be done in Java using the following example:
Java Configuration
@Bean
public Step step1Manager() {
return stepBuilderFactory.get(“step1.manager”)
.partitioner(“step1”, partitioner())
.partitionHandler(partitionHandler())
.build();
}
@Bean
public PartitionHandler partitionHandler() {
TaskExecutorPartitionHandler retVal = new TaskExecutorPartitionHandler();
retVal.setTaskExecutor(taskExecutor());
retVal.setStep(step1());
retVal.setGridSize(10);
return retVal;
}
It is possible to match the gridSize parameter to the size of the TaskExecutor’s thread pool by determining how many discrete step executions to produce. To reduce the size of the work blocks, set the number of threads available to be greater than the maximum value.
IO-intensive Steps, such as copying vast amounts of files or replicating file systems into content management systems, can benefit from TaskExecutorPartitionHandler implementations. A step implementation can be provided for remote execution that acts as a proxy for remote invocation (such as using Spring Remoting).
Partitioner
If you need to generate new step execution contexts as input parameters, the Partitioner is the best choice for this task (no need to worry about restarts). The interface definition shows that it contains only one method:
public interface Partitioner {
Map partition(int gridSize);
}
Each step execution is associated with an ExecutionContext, which is returned as the return value of this method. Batch metadata shows up as a StepExecutionName later in the Batch metadata. For example, it could contain a range of primary keys or the location of an input file in the ExecutionContext’s name-value pairs. It then binds to the context input using #…# placeholders (late binding in step scope), as shown in the following section.
All the step executions of a Job must have unique names (keys in the Map given by Partitioner), but there are no other particular criteria. A prefix + suffix naming convention, where the prefix is the name of the running step (which is unique in the job), and the suffix is merely a counter, would be the most straightforward approach to accomplish this (and make it relevant for users). In the framework, there is a SimplePartitioner that follows this pattern.
Using a different interface named PartitionNameProvider, the names of the partitions can be provided separately from the partitions. Only the names are queried if a Partitioner implements this interface. It’s possible to reduce the cost of partitioning by doing this. There must be a match between the PartitionNameProvider’s names and those provided by the Partitioner.
Binding Input Data to Steps
The PartitionHandler is particularly efficient if all stages have the same configuration and input parameters are constrained at runtime from the ExecutionContext. Spring Batch’s StepScope feature makes this simple (covered in more detail in the section on Late Binding). Partitioner output might look like this table if it creates ExecutionContext objects with an attribute key named fileName that points to a different file (or directory) on a step-by-step basis:
Example step execution names for Practitioner’s execution context, which targets directory processing, are shown in Table 1.
| Step Execution Name (key) | ExecutionContext (value) |
| filecopy:partition0 | fileName=/home/data/one |
| filecopy:partition1 | fileName=/home/data/two |
| filecopy:partition2 | fileName=/home/data/three |
In this case, the file name can be linked to a step utilizing late binding to the execution context.
Java Configuration
@Bean
public MultiResourceItemReader itemReader(
@Value(“#{stepExecutionContext[‘fileName’]}/*”) Resource [] resources) {
return new MultiResourceItemReaderBuilder()
.delegate(fileReader())
.name(“itemReader”)
.resources(resources)
.build();
}







