

What you read in this article:
Indexing/Replacing Documents in Elasticsearch
My name is Arsalan Mirbozorgi, and in this article, I want to let you know about managing data in Elasticsearch. In the last part, we talked about how to build an index.
If you have not read the first part, I recommend you to read it:
First example:
Now we want to tell you how you can add a document to your previous Index named Customer. We use the following request for that.


This command can make a document with id=1 and save it in an index which is called customer. If we repeat this command with the same document, then Elasticsearch will create a new document with id=1on the previous document.
Now we try a new command.
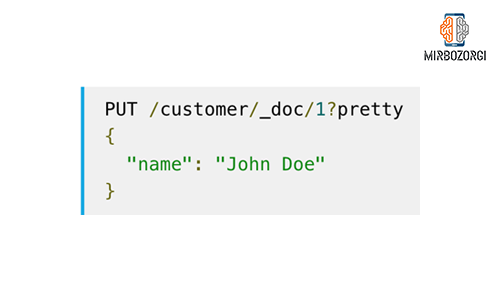

As you can notice, after GETing the new document the value of the name field has changed. In Elasticsearch you don’t need to specify an id value, If you don’t need to add an id to create a specific document, you can use the POST command. You can see an example, below.

As you can see in the -id- field, in this situation a random id is set for the document by Elasticsearch.
Update Documents in Elasticsearch
Elasticsearch, besides being able to index and replace documents, also can update a document. For doing this, first of all, Elasticsearch deletes the previous document and then indexes the updated document. In the following example, you can see how to update a document. In this example, the name field changes from John Doe to NilaSoftware.

As you can watch, after GETing the document, the name field value has been changed to NilaSoftware in the right way.

In the next example, we also add the age field to our document.

Sometimes in the update process, simple scripts are used. For example, we first increase the age of the document field to 10 using script. In the following example, “ctx._source” refers to the document itself, and “ctx._source.age” refers to the age field of that document.

After getting the document, we see that the age value has increased to 10.

Clear Documents in Elasticsearch
To erase document with id=2, we use the following api.

Batch Processingin Elasticsearch
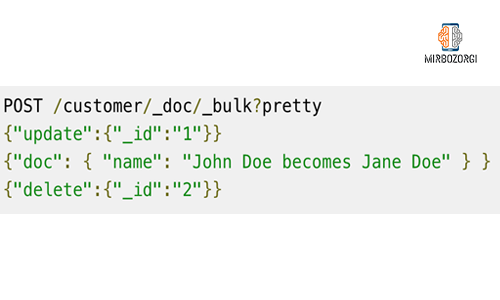
Another feature of Elasticsearch is that it can index, update and delete documents in batches. This point speeds up operations compared to the fact that operations are performed separately on each document. You can see 2 simple examples of this feature below.

Lately, we understand basic concepts such as Cluster, index, and big data about Elasticsearch. I, Arsalan Mirbozorgi, in this article try to introduce you to how to search among data in Elasticsearch. suppose that you have a document with the following design.

Loading sample data
First, download a data and index it in your cluster via the following command.
curl -H “Content-Type: application/json” -XPOST
“localhost:9200/bank/_doc/_bulk?pretty&refresh” –data-binary “@accounts.json”
After that, get your indexes.
curl “localhost:9200/_cat/indices?v”
This will get a response as follows.

The Search Api
There are two ways for searching data in Elasticsearch. One way is to search through the Rest Request URL and the other is to search through the Rest Request Body. The search that uses Request Body is clearer, and this search is done in a more readable format in JSON.
In this article, we will understand the search through the Rest Request Body, but to help understand these searches, we will examine an example of a search with the Rest Request URL.
For using this type of search, we use an API with an endpoint equal to search_.

In Api, the parameter q=*indicates that Elasticsearch loads all documents.

The above phrase shows that all available documents should be sorted in ascending order using the account_number field. In the following, we review some examples of fields used in elasticsearch.
took :
This indicates that the stretch time by elasticsearch is in milliseconds.
timed_out :
Time shows whether or not the head is out.
shards_ :
It shows the number of shards on which the head was carried out, as well as the number of successful and unsuccessful shards.
hits :
Displays the Sarch response.
hits.total :
Indicates the number of documents that are consistent with ourarch parameters.
hits.hits :
Displays real arrays (real data).
hits.sort:
The key is sorting.
Now we want to do a search operation like the previous example and this time we do it through Rest Request Body.

Introduction to query language in Elasticsearch:
Example:
Here is the field to search all documents in a specific index.

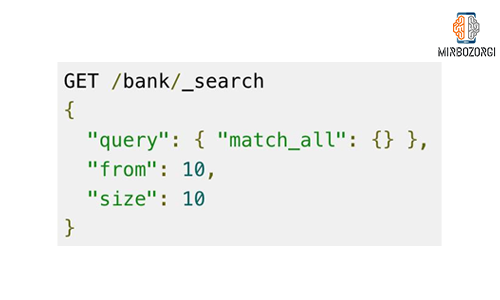
In the next section, we add the size expression and place its value equal to 1. This will allow only one document to be returned in response.

The size value by default is always equal to 10. In this section, the phrase from means determining which document to start from and how many documents to return according to the size value. The value of the phrase from by default is equal to zero.

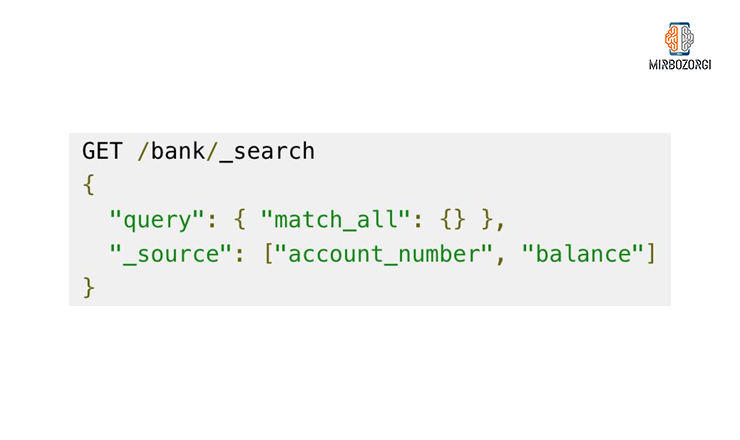
In the above request, all documents are returned in descending order by the Balance field. Till now, you get familiar with some basic parameters and you can do more advanced resources from now on. In the following example, you can see that with the two fields balance and account_number, you can receive the following request.
request after running fields:
In this section, we are going to use a new query called the match.
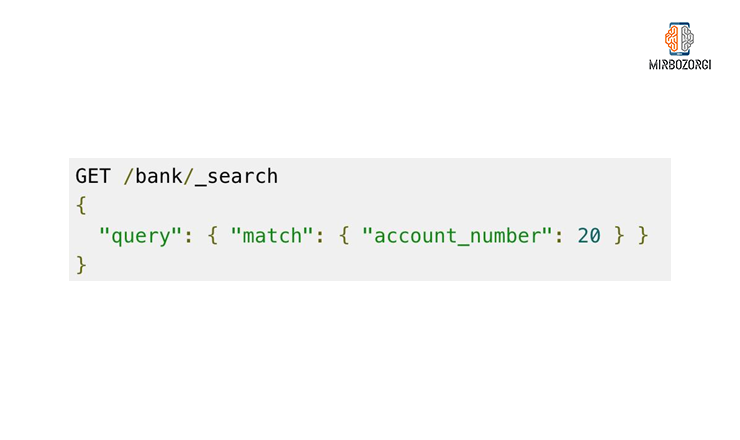
Think that we want to find a document with an account_number equal to 20. For this purpose, we use the following commands.
Response of these commands will be as follows.
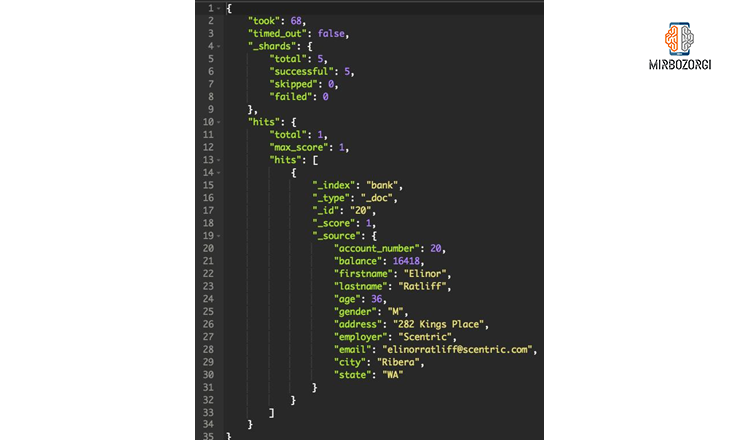
As you can see, only one document with account_number equals 20.
Second example Elasticsearch:
For better understanding, let’s look at another example.

In this section, in the address field, all documents that have mill and lane values, are displayed. To specify that documents that contain exactly the phrase mill lane are displayed, we need to use a query called match_phrase.
There is another query called bool. This query must display all smaller queries in a larger query. This is done in a logical way called boolean. In the following example, by using match query twice, all documents that contain mill and lane values are displayed in the address field.

Response of these commands will be as follows.
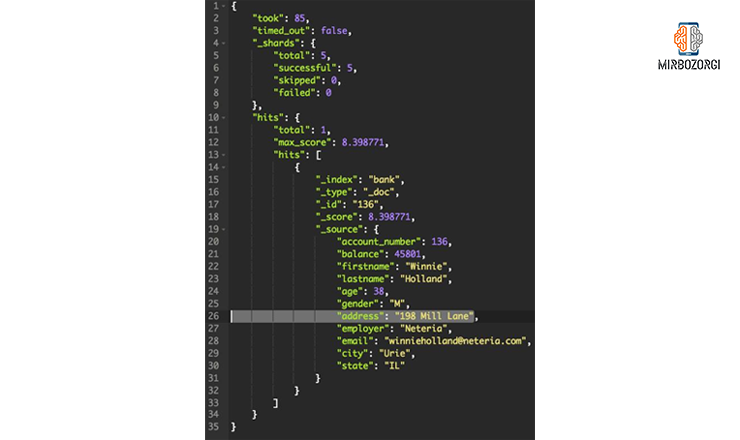
look at the highlighted address field here carefully. This field contains both mill and lane values. The word “must” in the request means that getting a value of true for both query bools is necessary for displaying the document.

In the above request, you can see a new query called should. When we use this query, if only one of the bools has the value of true, documents will return.

In the example code above, you will see another new query called must_not. This query does not return any documents containing mill and lane values in the address field when used.
Now let’s check another example. In this example, we want to display documents that have age values equal to 40 and their state is not equal to ID. For this, we use the following code.

Apply filters in Elasticsearch
You have that in your mind that in the Search Api section we skipped the document score review. In this section, we want to give you a brief description of the score in Elasticsearch. score in Elasticsearch is a numeric value and is set based on the coordination of document and query in the request. In some situations scoring is useless. For example, the Elasticsearch system does not generate a specific score value for documents because this scaling will have virtually no effect on filtering a specific field in Elasticsearch. In the query bool that we introduced in the previous section, the filter condition is used to apply filters to documents.
Last example:
Here we end the discussion with another example. In this example, with query range, with range, we can filter documents based on different values of a field. The range query is used to filter numeric values or dates.
The following example shows accounts with balance values between 20,000 and 50,000.
yed.








